
Czy kiedykolwiek zastanawialiście się, dlaczego w ostatnim czasie na polskich portalach społecznościowych pojawia się coraz więcej artykułów, w których każde słowo w tytule pisane jest wielką literą, na przykład „Rewolucyjny System Wprowadzony Przez Firmę ABC”? Ten sposób formatowania tytułów, znany jako kapitalizacja każdego wyrazu (ang. title case), cieszy się dużą popularnością w krajach anglojęzycznych, a szczególnie w Stanach Zjednoczonych. Skąd jednak ta moda w Polsce? Wynika to z faktu, że wiele treści w mediach społecznościowych jest korygowanych i stylizowanych przez duże modele językowe, takie jak ChatGPT czy też Bard. Niestety, podczas treningu tych modeli, większość dostępnych tekstów jest w języku angielskim. Pomimo że duże modele językowe są efektywne w korekcie i redakcji języków innych niż angielski, czasami mogą nieświadomie przenosić pewne specyficzne dla angielskiego stylizacje i konwencje.
Innym wyzwaniem, przed którym stoją duże modele językowe, zwłaszcza te wielojęzyczne, jest fakt, że zazwyczaj są one dostępne wyłącznie w chmurze. Jest to problematyczne w sektorach takich jak bankowość, medycyna czy bezpieczeństwo narodowe, gdzie z powodu wymogów ochrony tajemnicy bankowej, lekarskiej, czy też ochrony danych o wysokim stopniu poufności, wykorzystanie chmury obliczeniowej – niezależnie od tego, czy jest to chmura prywatna, czy publiczna – nie zawsze jest możliwe. W związku z tym, jakże korzystne byłoby posiadanie mniejszych, niezależnych modeli, zwłaszcza tych na licencjach otwartych, które można by uruchamiać na lokalnej infrastrukturze, umożliwiając bezpieczne przetwarzanie wrażliwych danych klientów czy pacjentów.
Aby zatem stworzyć własny model językowy lub dostosować istniejący, niezbędna jest duża ilość polskich zbiorów tekstowych.
Na świecie powstało mnóstwo projektów pracujących zarówno nad wielojęzycznymi modelami LLM, jak i bazami danych tekstowych, które mogą być zastosowane do ich trenowania. Wśród najbardziej znanych projektów baz danych tekstów należy wymienić Common Crawl (CC), OSCAR czy The Pile: projekt EleutherAI.
W lipcu 2022 r. został zaprezentowany LLM o nazwie Bloom, będący odpowiedzią europejskich naukowców na model GPT-3. W zaledwie w roku czasu ponad 1000 naukowców z ponad 250 zaangażowanych w projekt instytucji z 70 krajów stworzyło najlepszą alternatywę dla narzędzia OpenAI. Sam trening modelu trwał 117 dni!. Bloom działa w 46 językach naturalnych, ale niestety w momencie startu zabrakło wśród nich języka polskiego.
Brak obsługi naszego języka w modelu Blooom nie umknął oczywiście uwadze środowiska zainteresowanego rozwojem AI w Polsce. Podczas jednego z odcinków podcastu nieliniowy.pl, jego autor Michał Dulemba zapytał swojego rozmówcę, kto może wpłynąć na próbę polonizacji Blooma. Sebastian Kondracki, Chief Innovation Officer w firmie Deviniti, autor książki pt. „Python i AI dla e-commerce”, podjął rzuconą rękawicę i przyjął wyzwanie, a niedługo później powstał projekt Spichlerz.
Polacy nie gęsi, iż swój język mają
Spichlerz to prężnie rozwijająca się inicjatywa stworzenia bazy zróżnicowanych tematycznie tekstów wysokiej jakości (tj. mających dużą wartość treningową, niekoniecznie w pełni poprawnych językowo), napisanych w języku polskim. Zbiór danych Spichlerza ma w założeniu umożliwić wytrenowanie dowolnego modelu LLM, który mógłby być podstawą aplikacji sprawnie operujących w języku polskim. Opracowywane w ramach projektu Spichlerz zbiory danych są dostarczane z manifestami opisującymi licencje tekstów oraz rozbudowane metryki pozwalające wstępnie te teksty scharakteryzować.
Na przykład, indeks czytelności FOG oraz złożoność leksykalna (ang. lexical density) dostarczają informacji o stopniu przystępności treści. Liczba symboli, w tym znaków interpunkcyjnych, pozwala ocenić, czy materiał nadaje się do wykorzystania w trenowaniu modeli językowych, zwłaszcza poprzez wskazanie, czy zawiera on wyłącznie tekst, czy też inne typy danych. Proporcja znaków interpunkcyjnych do liczby słów pomaga zidentyfikować rodzaj tekstu, na przykład czy jest to tekst ciągły, lista, czy ankieta z licznymi miejscami do wypełnienia.
Stosunek liczby rzeczowników do czasowników w tekście również wnosi istotne informacje. Przewaga rzeczowników może wskazywać na ciąg nazw własnych, teksty naukowe, lub prawne. Ta metryka, podobnie jak indeks FOG, służy do oceny przystępności tekstu. Teksty z dominującymi formacjami rzeczownikowymi zazwyczaj są trudniejsze w odbiorze niż te z przewagą czasowników.
Dodatkowo, metryki takie jak średnia długość zdania lub słowa dostarczają informacji o czytelności tekstu. Długie zdania i słowa, zwłaszcza te powyżej trzech sylab, zazwyczaj są mniej czytelne. Dane dotyczące użycia wielkiej litery w środku słowa (camelCase) mogą wskazywać, czy tekst jest odpowiednio sformatowany i czy nie zawiera on przypadkowych fragmentów kodu, nieprawidłowych odstępów, czy przerwanych linii.
Znaczne odstępstwa od wartości średnich lub środkowych (średnia arytmetyczna, mediana) w przypadku każdej z tych metryk każą przyjrzeć się uważniej odpowiednim plikom, ponieważ może (ale nie musi) to być sygnałem, że tekst nie nadaje się do trenowania. Tak jak na poniższym wykresie, gdzie istotnie wyższa niż przeciętnie liczba symboli świadczy o potencjalnych problemach z formatowaniem.
Ilustracja 80. Porównanie liczby symboli w dwóch zbiorach – wykresy pudełkowe pozwalają na szybkie wykrycie wartości odstających.
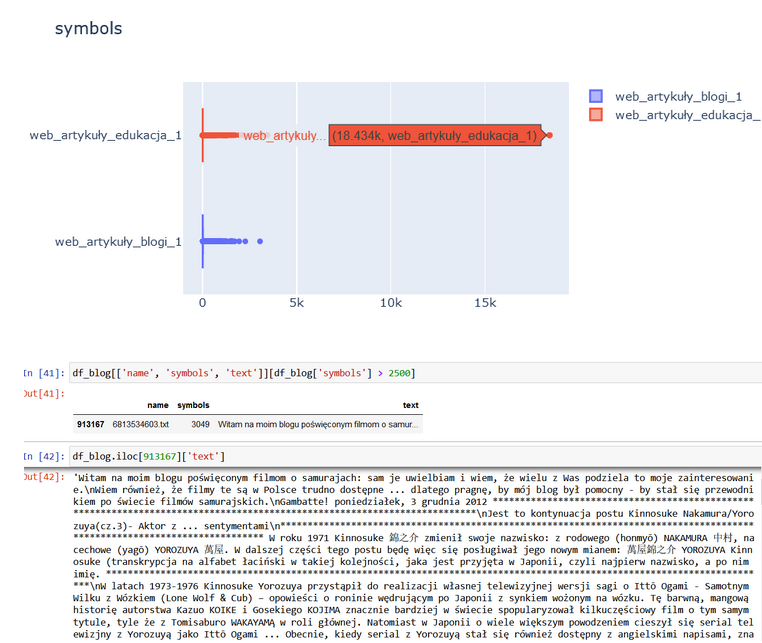
Źródło: opracowanie własne SpeakLeash
Niezwykle cennym parametrem w manifestach jest kategoria tematyczna. Zespół Spichlerza opracował klasyfikator, który obecnie rozpoznaje 118 kategorii (na razie nie ma kategorii pornografia/hazard, zostanie dodana w przyszłości). Dzięki temu użytkownik może wybrać tylko te kategorie tekstów, które faktycznie są dla niego interesujące lub dane z jednej szerszej dziedziny (np. wszystkie kategorie związane ze zdrowiem: zdrowie, uroda, rehabilitacja, poradnia, szpital, dieta).
Dzięki tym informacjom łatwo jest przefiltrować i dopasować dostępne dane do projektów zarówno badawczych, jak i komercyjnych. Zaproponowane w manifestach metryki umożliwiają porównywanie kilku zbiorów, co może w przyszłości stanowić nieocenione źródło danych dla projektów naukowych, np. językoznawczych, neurolingwistycznych czy interdyscyplinarnych.
Ilustracja 81. Porównanie odsetka czasowników w dwóch zbiorach – na histogramach widać, że teksty z blogów są bardziej dynamiczne (a więc prawdopodobnie łatwiejsze w odbiorze) niż teksty ze stron edukacyjnych.
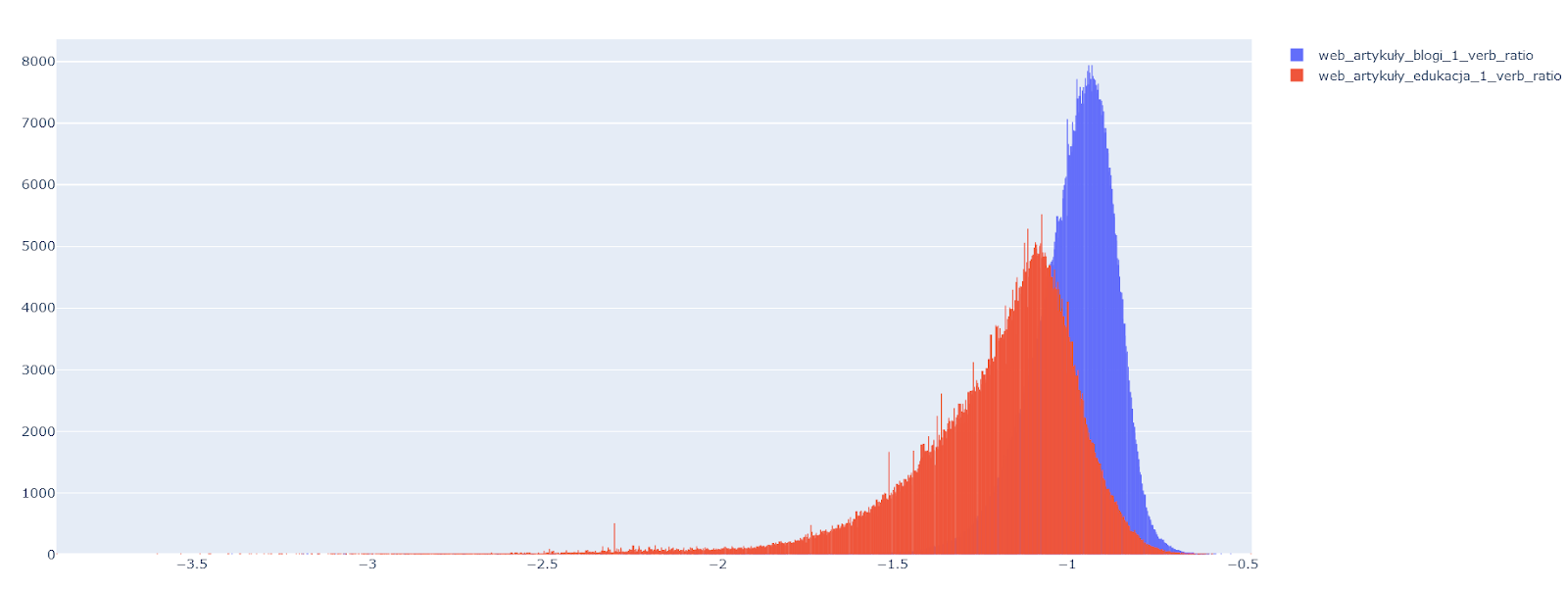
Źródło: opracowanie własne SpeakLeash
PRZYSZŁOŚĆ PROJEKTU
Projekt ten już teraz zalicza się do jednych z największych inicjatyw typu open-science na świecie, koncentrujących się na ewidencji, gromadzeniu i przetwarzaniu dużych zbiorów danych. Stan na grudzień 2023 roku to imponujące ponad 833 GB polskich tekstów. Dla kontrastu, pierwsza wersja projektu The Pile, która wspierała rozwój modelu GPT-NeoX, obejmowała 821 GB tekstów w języku angielskim. Obecnie projekt skupia się głównie na tzw. czystych tekstach (tj. tekstach bez anotacji, które są potrzebne, na przykład, do uczenia nadzorowanego czy dostrajania modeli), ale już trwają prace nad tworzeniem zestawów zawierających instrukcje.
Przykład takiej instrukcji to:
Instrukcja: Skoryguj podany tekst
Wejście: ala ma kota
Wyjście: Ala ma kota.
Ilustracja 82. Dashboard projektu Speakleash
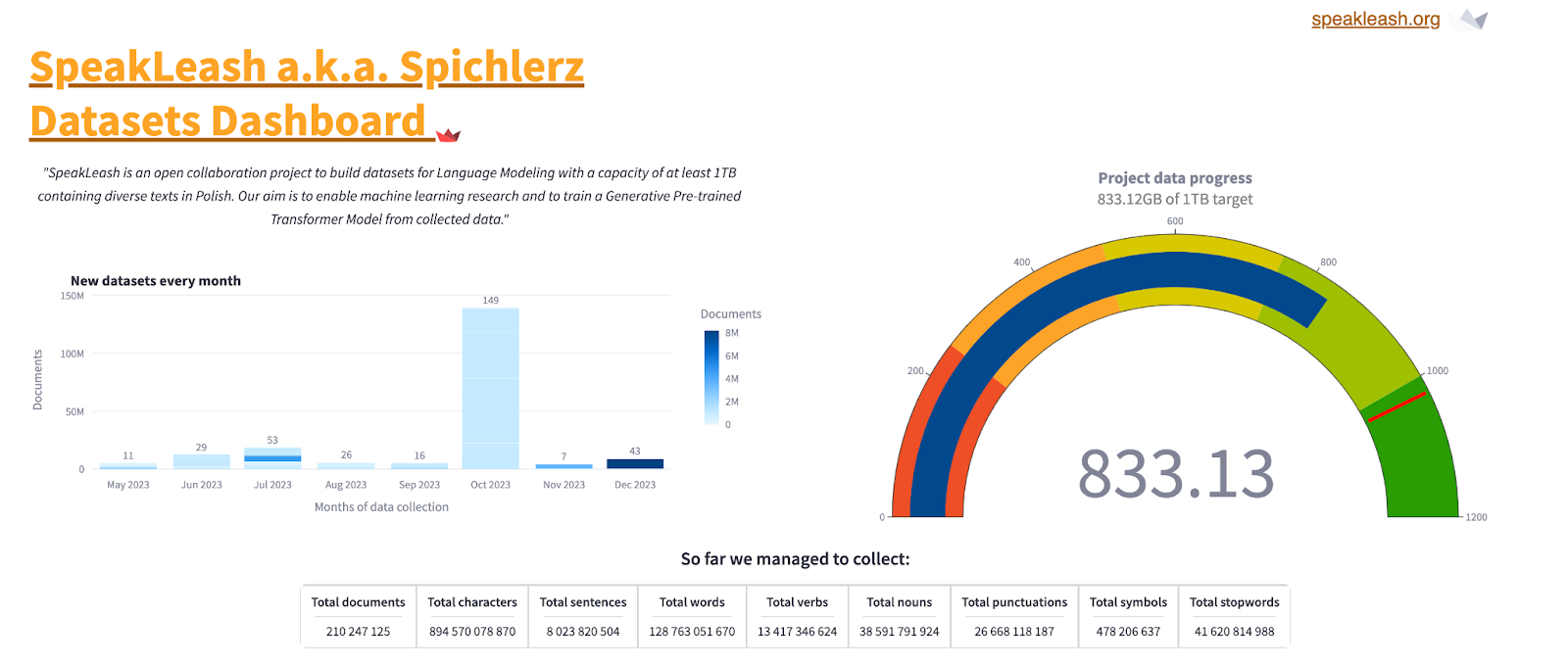
źródło: https://speakleash.streamlit.app/ (dostęp: 12.12.2023)
Twórcy projektu chcą też dalej rozwijać narzędzia do kontroli jakości (quality assurance/data curation): wykrywanie obraźliwych treści, podobnych do siebie tekstów itp. Mają nadzieję udostępnić przygotowane zbiory danych różnym grupom badawczym czy firmom pracującym nad technologią AI – w Polsce i za granicą – co zaowocuje pierwszorzędnym wsparciem dla języka polskiego w przyszłych projektach. Dzięki metrykom czas poświęcony na czyszczenie danych treningowych może się znacząco skrócić, co potencjalnie przyczyni się do redukcji kosztów lub podniesienia jakości produktów i usług oferowanych przez osoby korzystające z zasobów Spichlerza.



